FugakuNEXT is the codename for the follow-on flagship supercomputer for Japan after Fugaku. RIKEN is the development lead for the system, Fujitsu holds the design contract,1 and NVIDIA will supply the GPUs.2 It is slated to be deployed in Kobe in 2029 and enter operations in 2030.
- Over 3,400 nodes3 and 15K GPUs4
- 20x application speedup over Fugaku and 60x over K computer
- FP64 performance:
- bf16 performance:
- fp8 performance:
- Memory:
- Less than 40 MW6 (target 30 MW)4
System architecture
Per the initial announcement,4
- CPU: Fujitsu Monaka-X (ARM with SME and a possible NPU)
- 1.4 nm with 3D chiplets
- SVE2 for vector, SME2 for matrix
- NVLink-C2C
- GPU: NVIDIA “next-gen” GPU
- Host-Device: TBD coherent interconnect
- Scale-up: NVLink within nodes and possibly between nodes
- Scale-out: Custom high-speed interconnect
It will also have a colocated IBM quantum system with a 156-qubit IBM Heron attached to the scale-out fabric.
The high-level design is as shown:5
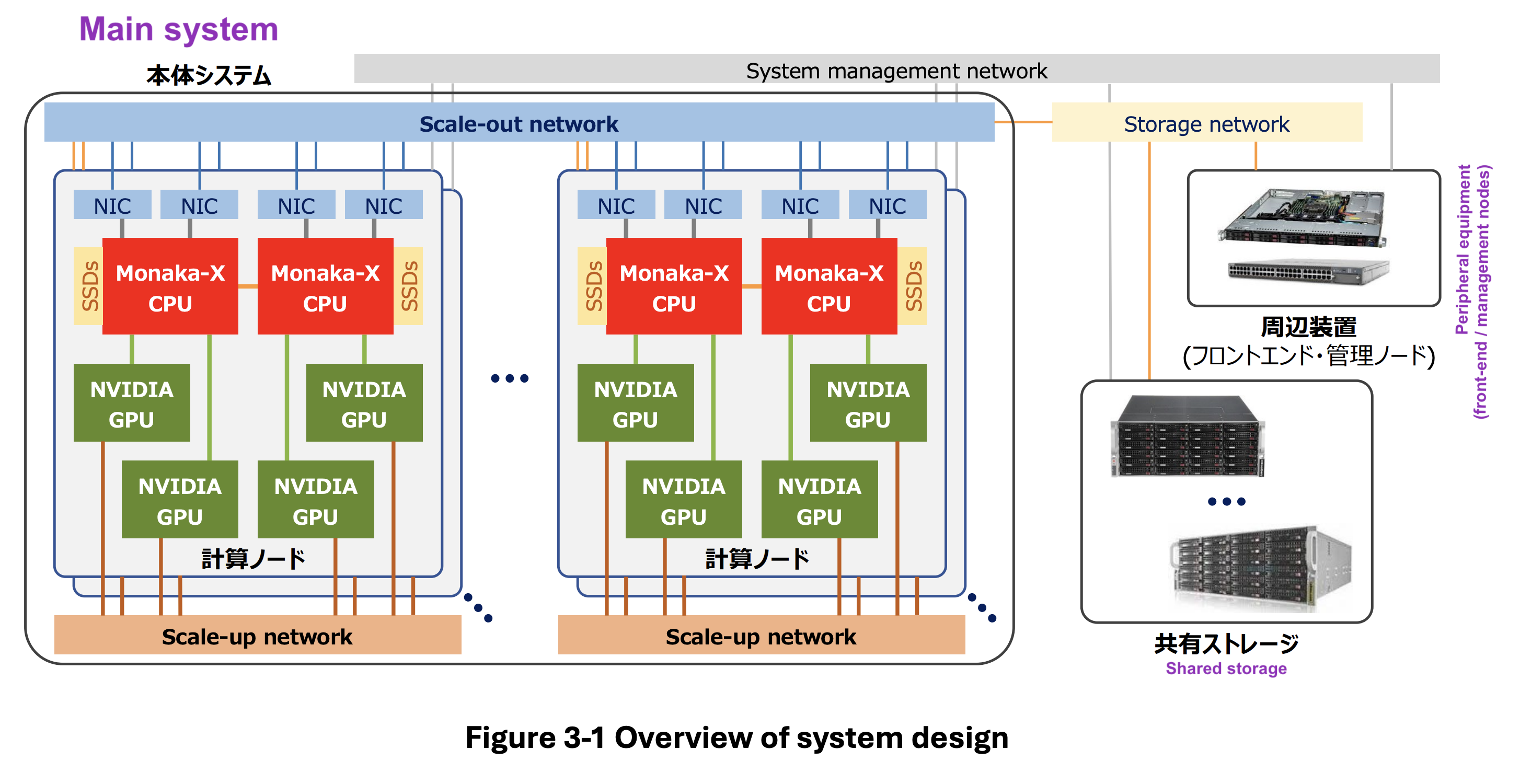
Undecided as of 2026
The following decisions were stated as being undecided in the 2026 Basic Design Technical Report5
- Scale-up network: NVL4 vs NVL72
- Scale-out network:
- Fujitsu proposed a quad-rail, rail-optimized fat tree with 64 nodes per group
- NVIDIA proposed a two-level fat tree with Spectrum-X Ethernet
- Storage (see below)
Storage subsystem
FugakuNEXT will have a two-tier storage hierarchy:5
- Tier 1: High-speed node-local storage. All-flash.
- Tier 2: High-capacity storage shared by all compute nodes
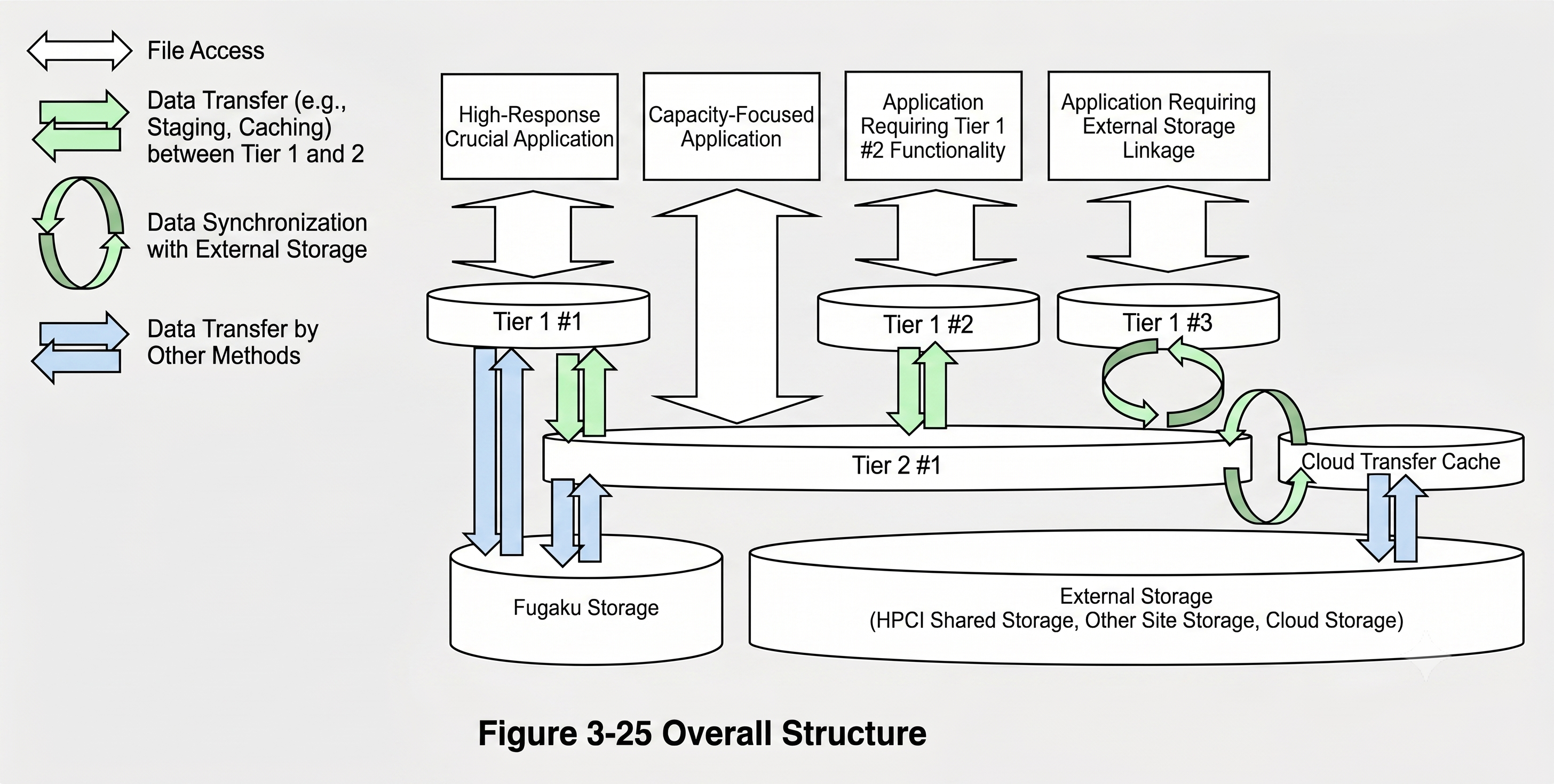
The Tier 2 file system is a traditional parallel file system with a few new feature requirements such as virtual namespaces.
The Tier 1 file system is less well-defined. VAST, Weka, and Scality are all mentioned as candidates for this, but only Weka meets the requirement of being able to deploy node-local. The 2026 design report5 also discusses a lot of uncertainty around how node-local SSDs will be presented to applications: as literal local file systems, through a distributed client-side namespace, or something else.
Performance targets
Satoshi Matsuoka presented the following targets for simulation workloads at Salishan 2025:6
- Raw hardware performance gain: 10x - 20x
- Mixed precision or emulation: 2x - 8x
- Surrogates / PINN: 10x - 25x
- Total: 200x - 1000x or more over Fugaku (“Zettascale”)
The system performance requirements for the RFP3 and reinforced in the initial NVIDIA announcement4 are:
| Metric | CPU | GPU |
|---|---|---|
| FP64 vector | 48 PF | 3,000 PF |
| FP16/BF16 matrix | 1,500 PF | 150,000 PF |
| FP8 matrix | 3,000 PF | 300,000 PF |
| FP8 matrix, 2:1 sparse | 600,000 PF | |
| Memory capacity | 10 PiB | 10 PiB |
| Memory bandwidth | 8 PB/s | 800 PB/s |
The storage subsystem will be two tiers:3
| Tier | Architecture | Implementation | Bandwidth | IOPS | Capacity |
|---|---|---|---|---|---|
| First | Near-node local | Something like CHFS, BeeOND | Write memory in less than 1 minute | Open/close/stat file per process in under 1 second | 2x memory |
| Second | Shared | Lustre, DAOS | 20% of first tier | 10% of first tier | 30x memory |
Timeline
The project timeline is as follows:3

After the announcement of NVIDIA being selected as the GPU provider,4
- 2025: Phase-1 testbed (~200 GPUs)
- 2026: Phase-2 testbed (~2000 GPUs)
- “more than” 400 GB200 superchips (inferred from the claims of 40 TF FP64/GPU)
- XDR InfiniBand (nonstandard with B200)
- Liquid-cooled Supermicro servers
- Photo of a GB200 NVL72 suggests this is NVL72
- “Quantum HPC Collaboration Platform” will be merged in as well to provide ~400 more GPUs
- 2027: Phase-3 testbed with Fugaku-NEXT-like architecture (?? GPUs)
- 2030: Full Fugaku-NEXT with 15K GPUs
Early vision
The details of the project were summarized on a digital poster at SC24:

Satoshi Matsuoka has been talking about their vision for FugakuNEXT since around 2022. The vision for its CPU is:7
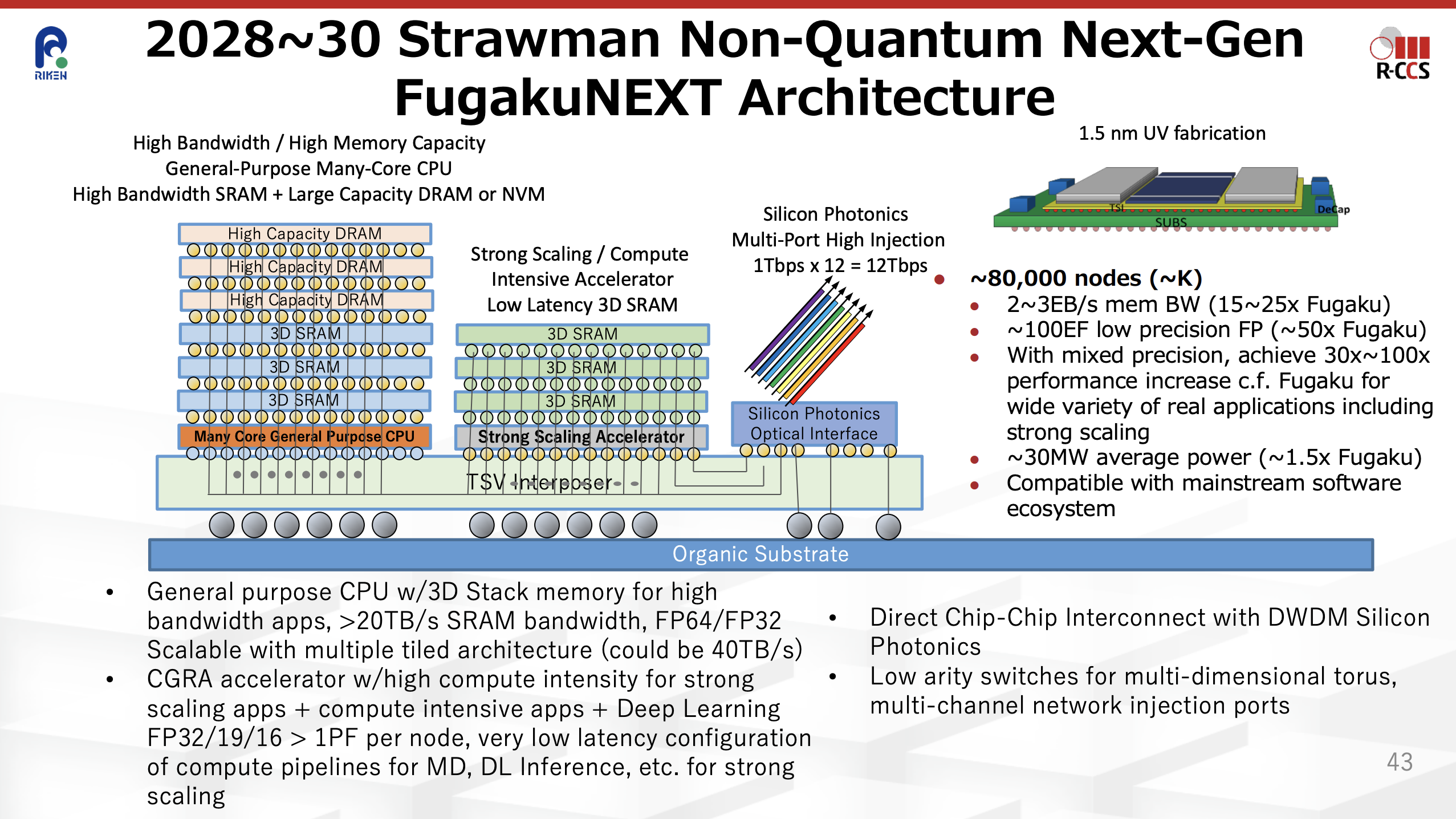
Themes that may be relevant to a processor or node include:73
- 3D stacking of memory and logic (as depicted above)
- Silicon photonics
- Large SRAMs, a la AMD 3D VCache
- Specialized tensor core-like data paths for scientific motifs like stencils, convolution, FFTs
- CGRA instead of or in addition to SIMD
- Processing-in-memory (PIM)
The CGRA is called out as a “strong scaling accelerator” candidate, so perhaps the CPU socket will have tiles of general-purpose CPU cores as well as CGRA tiles.
Footnotes
-
Fujitsu awarded contract to design next-generation flagship supercomputer FugakuNEXT ↩
-
https://www.riken.jp/pr/news/2025/20250822_1/index.html ↩ ↩2
-
https://www.mext.go.jp/content/20250822-mxt-jyohoka01-000044312_41.pdf ↩ ↩2 ↩3 ↩4 ↩5
-
Basic Design Technical Report for the New Flagship System “FugakuNEXT” ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9 ↩10