Multi-plane fat tree is a topology where each node has multiple NICs, and each NIC connects to its own independent (or semi-independent) fat trees.
Rail-optimized InfiniBand
NVIDIA calls this “rail-optimized” and uses a configuration whereby:
- Each GPU is associated with an InfiniBand HCA (NIC) within an eight-way DGX-like node
- Each of the eight NICs connect to a different leaf switch
- each node connects to eight different leaf switches
Downside: You need eight switches and eight different GPU nodes in close physical proximity to be able to use copper cabling in this configuration. This means high-power racks and high-density nodes (probably liquid cooled). The alternative is to eat the cost of using a lot of (expensive) optics to connect nodes to leaf switches.
Upside: A wider pool of GPUs can talk to each other using a single switch hop. For example, using 64-port 400G NDR InfiniBand switches:
- With rail-optimized, you can connect 32x GPU nodes to a single switch
- Without rail-optimized, you can connect only 4x GPU nodes to a single switch
Spreading GPUs out like this provides more local paths, reducing potential congestion above the leaf switches.
Topology diagram
Multi-plane or rail-optimized fabrics look like this:
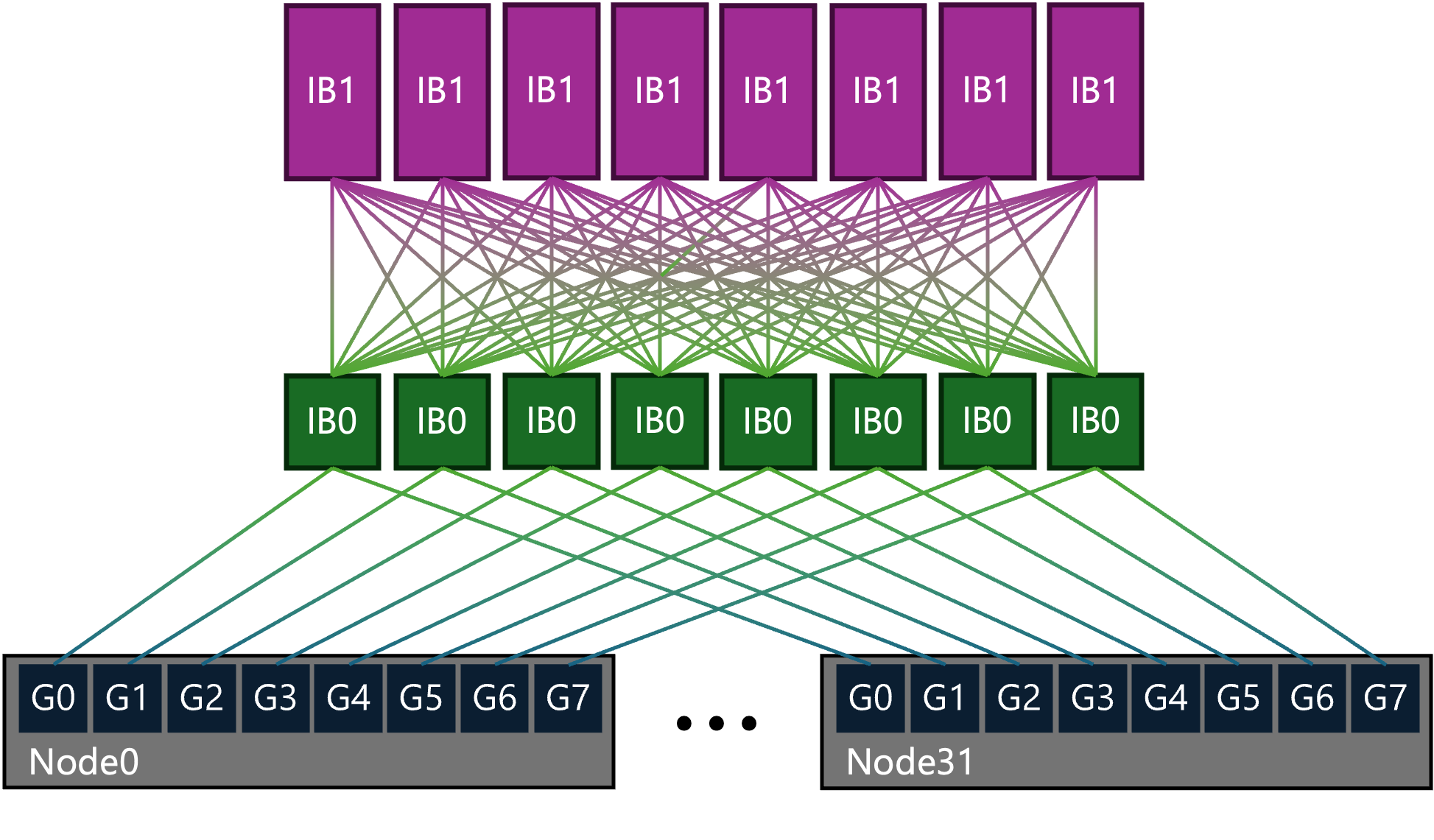
In the above, there are eight planes (rails). Compute nodes have eight GPUs and eight NICs (G0 to G7), and each GPU is connected to its own plane’s leaf switch (IB0). Each plane’s leaf switch is then connected up to every spine switch (IB1).
While the above is simplified, this can be done to very large scales:
- The leaf switches (IB0) and GPU/NICs are assembled into groups of eight switches (one per plane) and 32 nodes (256 GPUs). These groups can be scaled out to the limit of the size of the spine (IB1) layer.
- The spine (IB1) layer is shown as eight individual switches, but these can be logical switches. For example, each spine above may be a single physical 64-port switch, or it can be a two-level nonblocking fat tree with 16 spines and 32 leaves. This effectively acts like a single 1024-port director spine switch.
Assuming 64-port switches, the maximum scale for a nonblocking eight-plane fabric is:
- 8 virtual spine switches, each with 48 physical switches
- 16 physical spine switches within
- 32 physical leaf switches within
- 1,024 downstream ports per virtual spine
- 8,192 downstream ports total
- 32 leaf groups, each with 8 leaf switches
- 256 ports up, 256 ports down
- 8 planes (rails), one per leaf switch
- 8192 GPUs/NICs total
This can get even bigger if you introduce a taper.