- Tensor core is NVIDIA’s name
- Matrix core is AMD’s name
Basic functionality
Tensor Cores and Matrix Cores implement operations in a single clock cycle, where
- is a matrix
- is a matrix
- and are matrices
AMD and NVIDIA describe MMA capabilities as supporting operations.
History
NVIDIA V100 (1st generation Tensor Core)
- , are FP16
- , are FP16 or FP32
- support 4x4x4 matrices (FP16)
- HMMA: 128 FP16 FLOPS (64 FP16 FMAs) per clock per Tensor Core
- 8 tensor cores per SM
- 80 SMs per GPU
NVIDIA A100 (3rd generation Tensor Core)1
- , are binary, INT4, INT8, FP16, BF16, TF32, and FP64
- supports 8x4x8 matrices (FP16)
- HMMA: 512 FP16 FLOPS (256 FP16 FMAs) per clock per Tensor Core
- supports 2x2x4 matrices (FP64)
- DMMA: 32 FP64 FLOPS (16 FP64 FMAs) per clock per Tensor Core
- 4 tensor cores per SM
- 108 SMs per GPU
NVIDIA H100 (4th generation Tensor Core)2
- , are FP8 (E4M3 or E5M2), FP16, BF16, TF32, FP64, and INT8
- supports 8x4x16 matrices (FP16)
- HMMA: 1024 FP16 FLOPS (512 FP16 FMAs) per clock per Tensor Core
- supports 4x2x4 matrices (FP64)
- DMMA: 64 FP64 FLOPS (32 FP64 FMAs) per clock per Tensor Core
- 4 tensor cores per SM
- 132 SMs per GPU
NVIDIA Blackwell (5th generation Tensor Core)
- I haven’t found an authoritative document for this yet.
AMD MI250X (CDNA2)
- 4 Matrix Cores per CU
- 220 CUs per GPU (110 per GCD)
AMD MI300X (CDNA3)
- 4 Matrix Cores per CU
- 304 CUs per GPU
NVIDIA describes their Tensor Core geometry using these funny diagrams from which you must extract the hardware capability of each Tensor Core generation. Their SDK documentation only includes the logical matrix sizes supported;3 it appears the CUDA runtime maps these to the hardware capabilities.
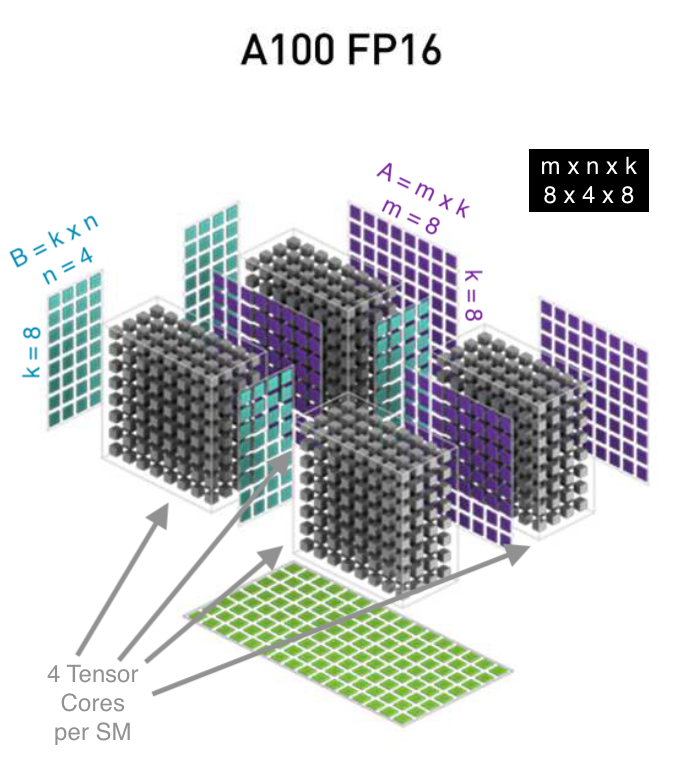
Simiarly the AMD SDK for Matrix Cores abstracts the underlying hardware dimensions.4
FLOPS per MMA
Per ChatGPT 4o:
To calculate the expression where , , and are all matrices, you need to follow these steps:
- Matrix Multiplication requires multiplications and additions per element
- Therefore, for each element: multiplications and additions, or FLOPS
- Total elements:
- Total floating-point operations for multiplication:
- Matrix Addition requires 1 addition per element
- Each element of the resulting matrix requires 1 addition
- Total elements:
- Total floating-point operations for addition: 16
Adding the operations from both steps gives
- Total FLOPS per GEMM
- So for FLOPS per MMA