This page is not up-to-date
This page only describes scaling laws that governed training dense transformers; I haven’t updated it to include the scaling laws that are being derived for mixture of experts models. The Kimi K2 paper describes this sparse scaling though.1
Transformer-based large language models have been shown to follow empirical scaling laws where model quality2 predictably improves as a function of parameter count and the training dataset size . While this was first published in 2020,3 these scaling laws have withstood the test of time over multiple orders of magnitude in scale of compute, data, and model sizes. For example, the performance of GPT-4 was predicted by Scaling law experiments that only used 0.1% of the compute resources eventually used to train the full model.4 Thus, these scaling laws now form the basis on which multi-billion-dollar supercomputers are sized.
If you have a supercomputer of a given size and you want to train for a fixed amount of time, scaling laws provide a means to calculate the ideal number of model parameters and size of training dataset. This is how all frontier models are now trained:
- A supercomputer is designed to fit a specific financial budget (e.g., a supercomputer that can process 10 EFLOPS at FP16 precision)
- A training time budget is set (e.g., train for three months so it can be released before a competitor)
- An optimal model size and dataset size is calculated using scaling laws to fit #1 and #2
- The model is trained until the dataset has been fully fed through, then training is stopped
This process of building a supercomputer and then designing a model for it is referred to as codesign.
Kaplan et al wrote the seminal paper about scaling laws in 2020 (see Kaplan et al (2020)) and the Chinchilla paper soon followed suggesting qualitatively similar but quantitatively different relationships between , , and (see Chinchilla (2022)). Every frontier model seems to have its own scaling law parameters, but they generally all follow a trend where
where and are the scaling law parameters that are a function of the specific way in which you will train a family of models; batch sizes, sequence lengths, dataset quality, and things like that play into this.
These scaling laws are very powerful, as they establish a direct, predictable relationship between model quality and supercomputer size. They are why:
- Sam Altman said that we could achieve AGI in just a few thousand days
- Ethan Mollick has asserted, “To get a much more capable model, you need to increase, by a factor of ten or so, the amount of data and computing power needed for training.”5
- NVIDIA is now releasing a new GPU every year6
- Why the scale of individual AI training clusters has been dramatically increasing
Applying scaling laws
In general, frontier models are now trained at scale using the following recipe:
- Design a supercomputer (e.g., 1 exaFLOPS FP16)
- Define a training time (64 days)
- Determine your compute budget ()
- Run scaling law experiments to parameterize the scaling law (determine and ) for the class of model you’ll be training
- Use the parameterized scaling law () to determine the optimal model size () and training dataset size () for your supercomputer
- Create a transformer of size and train it on tokens
What will result should be the best possible model that your supercomputer could’ve produced. Once you’ve got that, you build a new supercomputer using newer GPUs and more money, and you repeat the process.
Scaling law experiments
The scaling law experiment proceeds like this:
for compute_budget in compute_budgets: # in units of FLOPs
for model_size in model_sizes: # in units of tokens
# k is a constant that depends on batch size, sequence length, and
# other architectural features of a model.
k = flops_per_step / tokens_per_step # Kaplan found k = 1/(6N)
training_dataset = compute_budget / k
train_model(compute_budget, training_dataset)For each compute_budget, you form an isoFLOPs curve which exposes the balance point of model size and training dataset size.7 There is a minima for each isoFLOPs curve which represents the optimal model size and dataset size for a given compute budget. For example, this is what the isoFLOPs curve looks like for model size:8
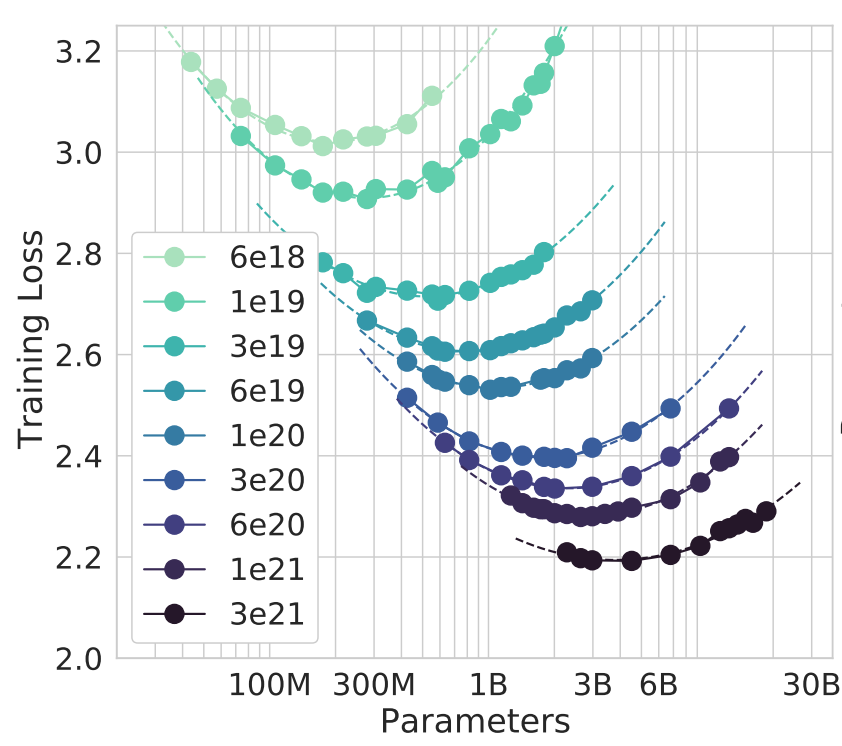
You can then plot these minima (values of or ) for each compute budget (values of ) on log-log scale and then do a linear fit to get parameters for the scaling law:8
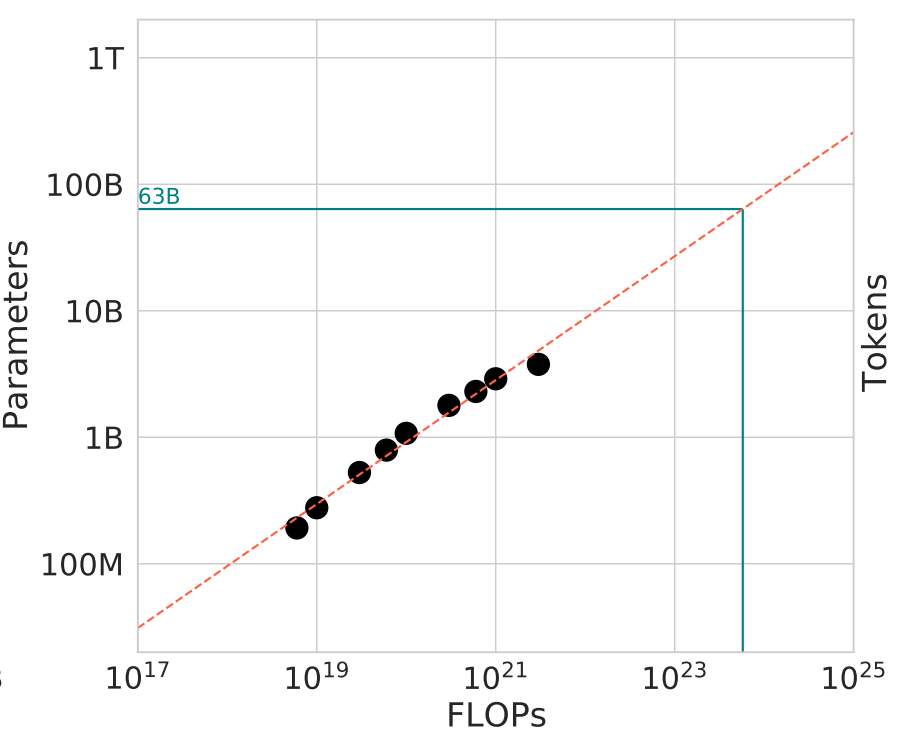
For the above diagram, you can fit this log-log data using and solve for as a function of :
Something similar can be done to establish the relationship between training dataset size and compute budget .
This means if you have a supercomputer of a given size (i.e., is fixed), you can calculate both the model size () and training dataset size () that will result in the best possible model that that supercomputer can train. This establishes the predictable relationship between model quality and supercomputer size.
In practice
Kaplan et al (2020)
In 2020, Kaplan et al3 found that the quality of a model improves predictably across multiple orders of magnitude. This established the basis for LLM scaling laws.
They showed that training a model with an ideally sized dataset is better than training a model to convergence. The optimal model for a fixed compute budget is proportional to . Formalizing this a bit,
- is a compute budget
- is the number of model parameters
- is the number of training tokens (dataset size)
And they found that:
They use cross-entropy loss function as an indicator of model quality.
Chinchilla (2022)
In 2022, Hoffmann et al from DeepMind published the Chinchilla scaling laws8 which state that the parameter count and dataset size should be scaled proportionally rather than the relationship described by Kaplan. They demonstrated this by comparing two models trained using the same number of FLOPs:
- a 70B parameter model trained on 1.4T tokens (Chinchilla)
- a 380B parameter model trained on 300B tokens (Gopher)
Their scaling law parameters came out to be:
That is, as you scale up your compute budget , you should increase your model size and training dataset size in roughly equal proportions.
They used perplexity and task-based evaluation to assess model quality instead of cross-entropy loss alone as Kaplan did. However, they found that loss and these “downstream” quality metrics all improve proportionately.
Llama 3.1 (2024)
Llama-3.1 found the optimal scaling law for was
where
- is a compute budget ( FLOPS)
- is the number of model parameters ( parameters)
- is the number of training tokens ( tokens)
This is quite different from the described by Kaplan et al3 and demonstrates the importance of performing your own scaling law experiments before training a new LLM.
AMD-135M
From AMD-Llama-135M, a relatively small transformer:
AMD-Llama-135M model was trained from scratch with 670 billion tokens of general data over six days using four MI250 nodes.
todo: Do the math here.
System two thinking
Quote
It turned out that having a bot think for just 20 seconds in a hand of poker got the same boosting performance as scaling up the model by 100,000x and training it for 100,000 times longer.
Fallibility and end of scaling
Recent work has shown that training on more data requires using higher precision to retain quality; conversely, quantization works against scaling laws. See https://arxiv.org/pdf/2411.04330.
Sam Altman has said that there are three dimensions (“key inputs”) to continuing to scale:9
- Compute
- Data
- Algorithms
He went on to say that these three can be traded off; for example, with excess compute, you can generate synthetic data. If you have much data, you don’t need as much compute (as shown with SLMs).
As of November 2024, Dario Amodei “believes that “scaling up” models is still a viable path toward more capable AI.”10
Footnotes
- ↩
-
Model quality was initially defined by validation loss, but later studies (e.g., PaLM-211) found that “downstream performance”—or the performance of a model on actual benchmark tests—followed the same pattern, establishing a proportionality between validation loss and actual usefulness of the LLM. ↩
-
[2001.08361] Scaling Laws for Neural Language Models ↩ ↩2 ↩3
-
According to the PaLM-2 report,11 you can calculate the dataset size for a compute budget and model size using in these scaling tests. ↩
-
[2203.15556] Training Compute-Optimal Large Language Models ↩ ↩2 ↩3
-
OpenAI’s Sam Altman: Microsoft partnership has been tremendously positive for both companies ↩
-
This Week in AI: Anthropic’s CEO talks scaling up AI and Google predicts floods: ↩