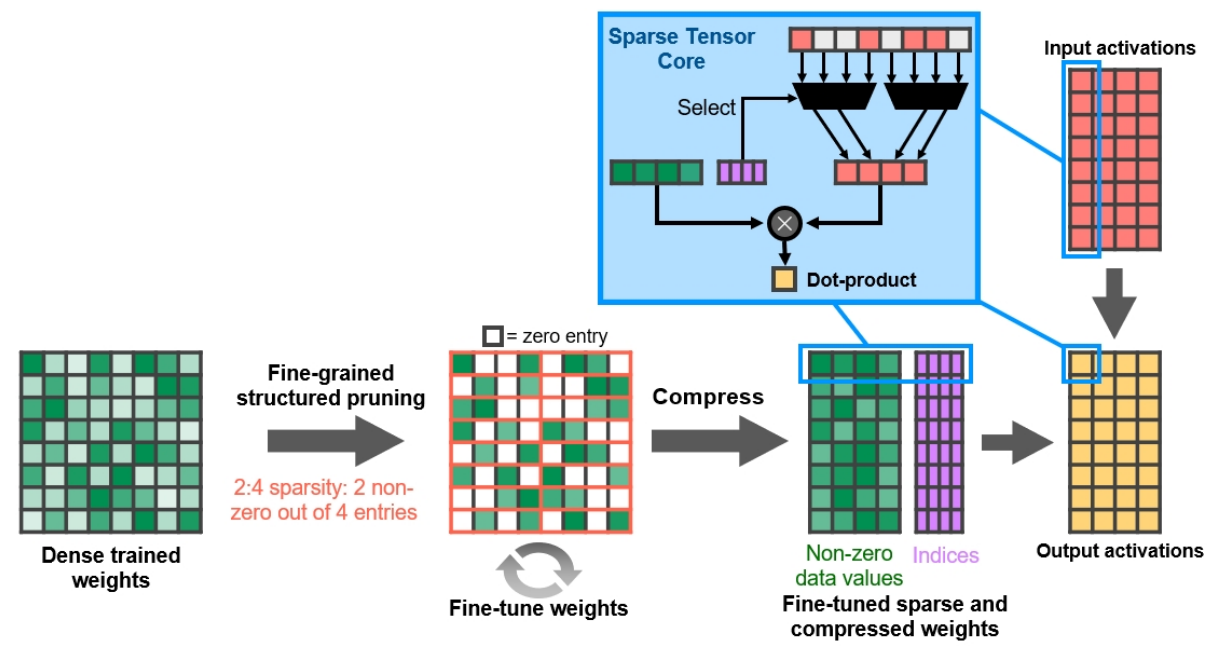
Newer NVIDIA tensor cores and AMD matrix cores also include Fine-Grained Structured Sparsity which is a technique for lowering the cost of LLM inferencing. It does nothing for training.
Using structured sparsity requires special handling of your model after it has been trained:12
- Train a model like normal.
- Use fine-grained structured pruning to drop out insignificant weights. This will reduce the number of parameters in the model by setting them to zero.
- Fine-tune the model to update the remaining weights to compensate for all the weights that were just set to zero.
The concept is:
- Enforce a specific sparsity pattern into the model, and the model will adapt around it
- Primarily an inferencing accelerator because “the structure constraint does not impact the accuracy of the trained network for inferencing.”
- Training with sparsity requires adding it early in the process, and “methodologies for acceleration without accuracy loss are an active research area.”
It’s called structured sparsity because you must zero out weights in a specific pattern. For example, “2:4 sparse matrix” allows two nonzero values in every four-entry vector: