LineShine (灵晟 or líng shèng) is an all-CPU exascale supercomputer at the National Supercomputing Center in Shenzhen (NSCC-SZ), built largely from domestically produced Chinese hardware. It debuted on the ISC26 Top500 list at #1 with an HPL of 2.1984 EFLOPS and a walltime of 16,181 seconds (4.5 hours).
See Tadashi Ogawa’s thread for authoritative references.
Jack Dongarra also rolled up many of the public details into a PDF report.
System Overview
| Site | NSCS, Shenzhen, China |
|---|---|
| Peak performance | 2.198 EFLOPS FP641 |
| Node count | 23,5522 |
| Processor | LX2 (ARMv9) |
| Interconnect | LingQi or LQLink3 (dual-plane fat-tree) |
| Bandwidth/node | 2x800 Gbit/s |
| Storage bandwidth | 10 TB/s |
The full system size is a bit mysterious, as the HPL run used more nodes than the first paper in which LineShine debuted, and some literature claims the system has more than 90 cabinets (which would be 23,040 nodes). The network diagram implies there are 184 frames, which is 92 racks, which is 23,552 nodes, and the system can scale up to 100,000 nodes.4
Compute Nodes
All nodes are dual-socket, CPU-only nodes, each with:
- 2x 1.55 GHz LingKun LX2 ARMv9 CPUs
- 2x dies, each with 152 cores
- each die has 8 clusters
- 304 physical cores
- 800G NIC integrated
- 2x dies, each with 152 cores
- 64 GB HBM at 8 TB/s (2x 32 GB HBM, 2x 8 stacks)
- 512 GB DDR (4x 128G, one per CPU die)
Performance per node (two CPUs) is as follows:5
| Precision | Vector | Matrix |
|---|---|---|
| FP64 | 120.6 | |
| FP32 | 241.2 | |
| FP16 | 482.4 | |
| INT8 | 1920 |
Both SVE and SME appear to use 512-bit vectors (see LX2), but the vector performance has not been publicly stated.
CPUs have “dedicated SDMA engines” that tier data between HBM and DRAM, much like how KNL used its MCDRAM like a cache for DDR.
Physical integration
The integration of nodes into systems seems similar to Cray EX or BullSequana XH.
- 8x compute nodes fit into a single compute blade.
- 16x blades per “frame”
- 2x frames per cabinet
Those cabinets appear to be arranged into rows of 20,6 each with
- 14x compute cabinets
- 6x network cabinets
- 3,584 nodes/row
- 7,168 CPUs/row
The diagram below suggests there are six full rows (84 compute cabinets) and a seventh partial row.
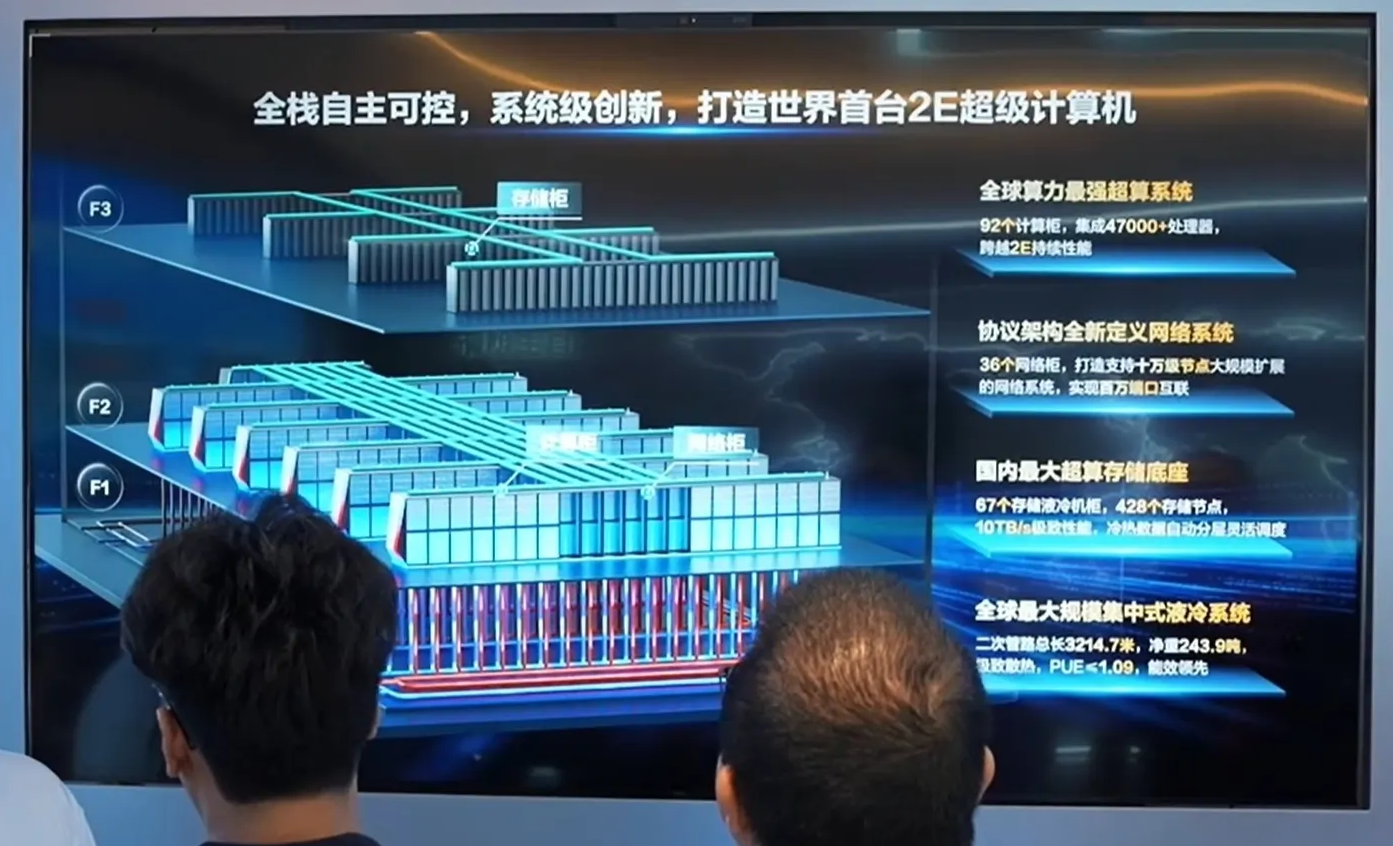
The datacenter integration appears to put the cooling on floor 1, the computer on floor 2, and the storage on floor 3.
Interconnect
The LingQi network uses a dual-plane multi-rail fat-tree. Each node has two 800G LQLink NICs,3 each connecting to its own independent tree.
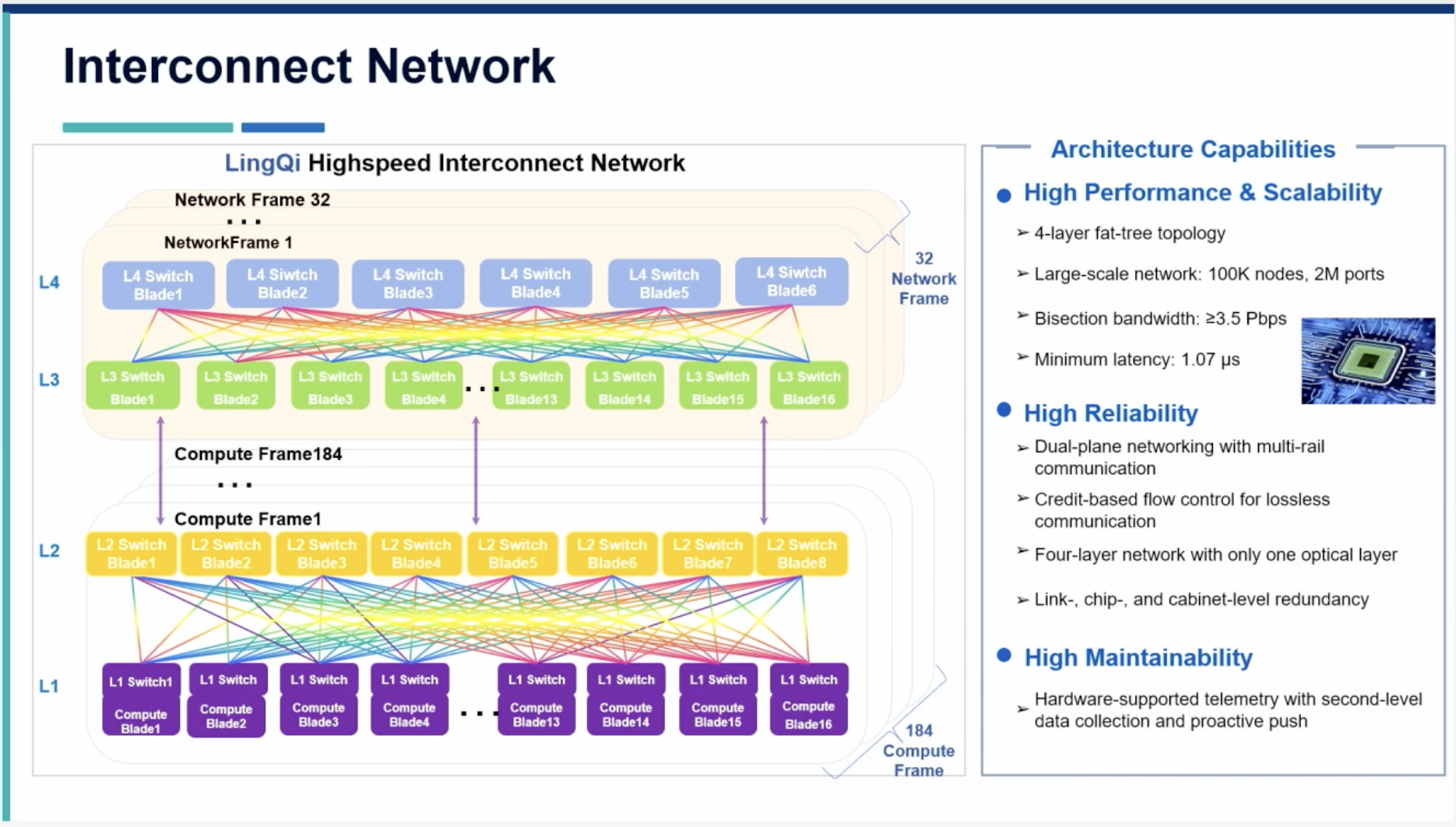
I think the network is implemented using 100G switching and links.
The first two levels of the tree are integrated within each rack such that a frame has:
- 16x L1 switches, with 800G downlink (probably 8x100G downlinks) to a node and 8x uplinks to 8x different in-rack L2 switches (probably 8x100G)
- 8x L2 switches, with 16 downlinks and ? uplinks.
The second two levels of the tree are centralized in dedicated network “frames” in dedicated network racks. Each network frame has:
- 16x L3 switches, with ? downlinks and 6 uplinks
- 6x L4 switches, each with 16 downlinks
Of the four levels, only one is optical.5 This is undoubtedly the L2-L3 network that connects compute frames to network frames, suggesting that the entire L3-L4 is copper. Given this spans 16 racks yet is copper, this further indicates that the links are 100G.
The most likely exact configuration is:
- Switches are 32x100G
- L1 (host leaf) has 2,944 switches (16x184 compute frames)
- 1x 800G host port down
- 8x 100G up to 8x different switches
- all copper
- L2 (frame spine) has 1,472 switches (8x 184 compute frames)
- 16x downlinks (copper) to 16x in-frame L1 switches
- 8x uplinks (optical) to 8 different network frames
- 2:1 taper based on cost (minimize transceivers)
- L3 (core leaf) has 512 switches (16x 32 network frames)
- 23x downlinks (optical) from L2
- 6x uplinks (copper) to 6 in-frame L4 switches
- residual 3:81:1 taper
- L4 (core spine) has 192 switches (6x 32 network frames)
- 16 downlinks (copper) to the 16 in-frame L3 switches
The end result is a steep 7.67:1 taper but with a very low optical cost, all achievable using 32x100G switching ASICs which should be well within the capabilities of Chinese domestic foundries.
The programming interface is UCX.5
The full deployment targets 36 network cabinets, though the system launched with 32.
Storage
The storage subsystem is divided into two “storage zones”:5
- “High Performance Tier”
- “Capacity Tier” with SSD storage pools and HDD storage pools
It is advertised as having 10 TB/s of bandwidth, likely at the high-performance tier.
Physically, it is implemented as:
- 428 storage nodes across 67 cabinets, each with 2 frames
- Liquid-cooled; described as China’s largest liquid-cooled storage deployment.
It may be a total of 200 PB with “plans” to expand to 1 EB.5
Software Stack
The nodes run Kylin Linux,1 and the software environment includes
- BLAS from the Kunpeng Math Library (developed by Huawei),7
- Hyper MPI (from Huawei)7
- OpenBLAS1
- OpenMPI1
PyTorch is also provided with an asynchronous MPI runtime to compensate for PyTorch’s CPU backend lacking CUDA stream semantics.8
Trivia
Yutong Lu said that LineShine (灵晟) translates to “intelligence” and “sun” or “success.”5 The decision to call it LineShine in English is part translation and partly phonetic.
Footnotes
-
This is inferred from the network diagram in Yutong Lu’s presentation at the Top500 session at ISC 2026, which shows 184 compute frames and 32 network frames. ↩
-
Term used in [2605.08633] Transforming the Use of Earth Observation Data: Exascale Training of a Generative Compression Model with Historical Priors for up to 10,000x Data Reduction. ↩ ↩2
-
See Yutong Lu’s presentation at the Top500 session at ISC 2026. ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Overview-Developer Guide-KML-KML (Math Library)-BoostCoredocument.devDocument-Kunpeng Community ↩ ↩2
-
[2604.15821] Breaking the Training Barrier of Billion-Parameter Universal Machine Learning Interatomic Potentials ↩