System architecture
There are a few differences between designing a supercomputer for AI and designing a supercomputer for traditional modeling and simulation. I once gave a presentation internally at Microsoft that contained this table:
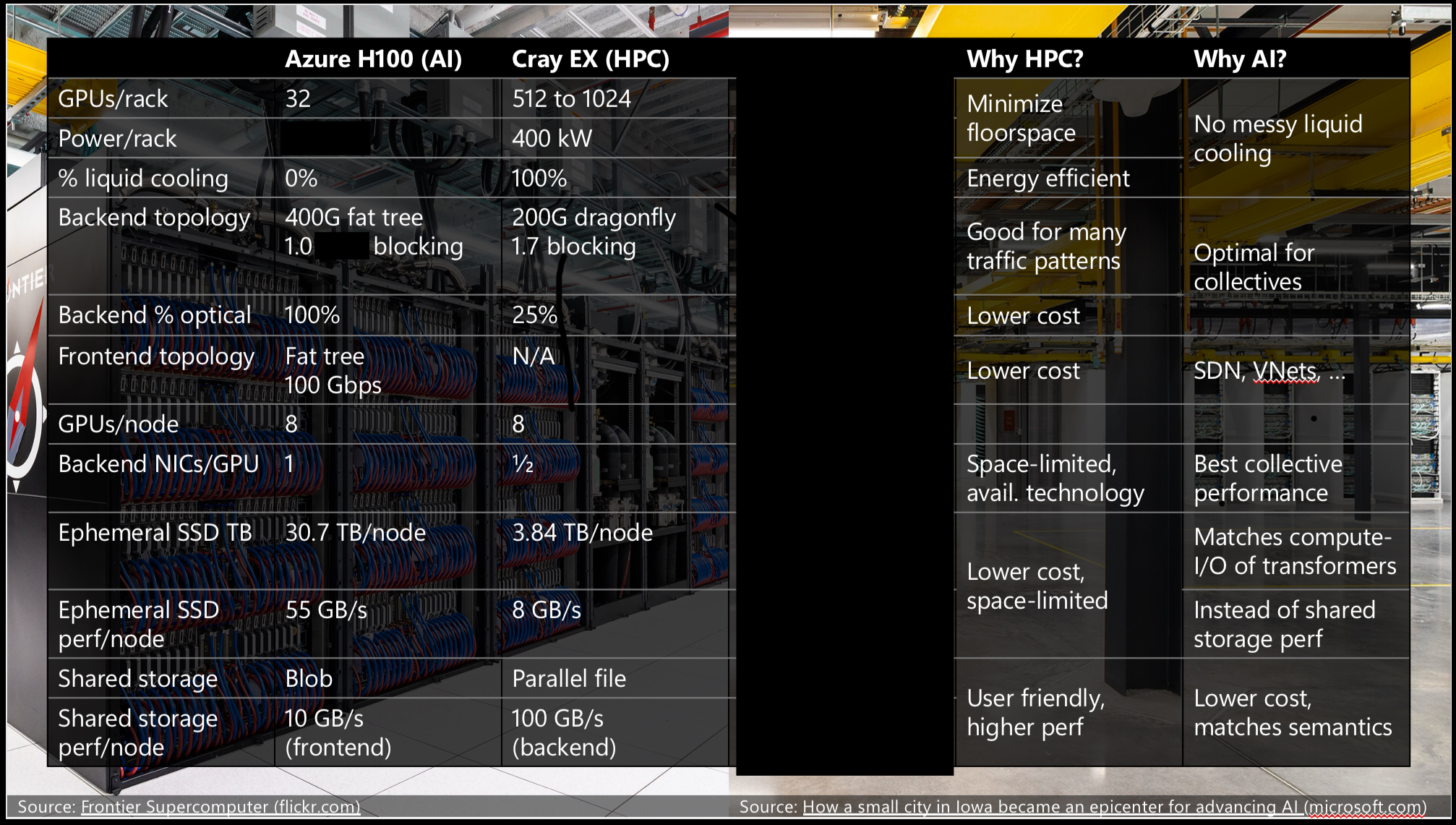
The biggest differences amount to:
- AI benefits from multi-plane fat trees. They make collectives faster since more nodes can talk to each other without hopping through switches, but they require more nodes and switches to be connected together in a small space. In practice, this requires using expensive optics instead of DAC cables.
- AI uses a lot of node-local SSDs for performance and capacity rather than a shared parallel file system. This requires more physical space within each node, making it harder to densely pack them within the reach of copper cables.
- AI uses a separate frontend network which has much less bandwidth to access remote storage. This is OK, because the I/O of training transformers is highly localized and requires relatively little capacity. This makes investing in local SSD capacity and performance more favorable than investing in remote storage capacity and performance.
These all leverage the unique aspects of AI model training that do not apply to more broad scientific workloads:
- Collectives are the predominant communication pattern in AI (see networking for LLM training, so optimizing the backend network for low-latency collectives is optimal. Point-to-point and low-latency communication isn’t as critical.
- The ratio of compute to I/O for training is ridiculously high (see storage for LLM training). This makes it easier to hide asynchronous data staging underneath computation, reducing the need for high-bandwidth access to high-capacity storage. Node-local storage is fine.
Rich Vuduc’s team developed an interesting model that can help quantify the advantages of designing a machine specifically optimal for LLM training, then understand how well it would perform for traditional modeling and simulation workloads.1
User interface
A common myth is that AI people use Kubernetes while HPC people use Slurm. This isn’t true; some AI shops use Slurm, and others use Kubernetes.
In addition, the needs of training versus inference are very different; Slurm makes very little sense for inference, whereas it maps naturally to the bulk-synchronous nature of training. As a result, we see some places like Black Forest Labs openly using Slurm for training and Kubernetes for inference.2
Slurm
The user experience for training an LLM on Slurm involves standard sbatch/srun with torchrun commands within the Slurm script. When a node crashes, the whole training job crashes.
- Meta uses Slurm on their big training clusters.3
- Mistral job ads indicate that they use Slurm.45 This makes sense, given their origins in Meta AI.
- NVIDIA also developed pyxis and enroot to make their AI training stack, which is containerized, work through Slurm.
- Black Forest Labs uses Slurm for their training infrastructure.2
Kubernetes
The user experience for training an LLM in k8s is hinted at by Microsoft AI6 and described in the Kueue documentation.
- User writes a training Python script that calls Ray APIs
- User fills in a RayJob manifest template with resource requirements and pointing to the script in step 1
- User submits the manifest via something like
kubectl apply -f job.yml - Kueue intercepts this new RayJob, creates a Kueue Workload object, and holds pod creation until resources are available
- When resources are available, Kueue admits the job. KubeRay then sees the RayJob and creates the RayCluster across GPU nodes
- The Ray head pod boots the rest of the Ray cluster, registers worker pods, runs the training script, and spins up Ray actors across all the workers
If a node fails, Ray detects an actor has died and restarts the worker on a spare node without tearing down the job. This statefulness across node crashes is what makes Kubernetes superior to Slurm for bulk-synchronous training; crashes and recoveries can be localized, lightweight, fast recovery operations.
AI labs that use Kubernetes for training include:
- OpenAI has disclosed that their AI training jobs are managed through Kubernetes.7
- Anthropic also uses Kubernetes internally.8 This is likely a result of their OpenAI heritage.
- CoreWeave also exposes its GPU instances through a managed Kubernetes service, CKS,9 but developed SUNK for its AI customers who want a Slurm-based scheduling interface for their AI jobs.10
- Microsoft AI uses Kubernetes in a layered way, along with Kueue and Ray.6
Unclear
Thinking Machines Lab comes from a mix of OpenAI and Meta DNA, and their job listings list Slurm and Kubernetes as examples of relevant experience.11
Footnotes
-
Are AI Machines Good for HPC?, presented at ISC25. The Calculon paper was presented at SC’23. ↩
-
Member of Technical Staff - ML Infra job ad for Black Forest Labs (greenhouse.io) ↩ ↩2
-
Revisiting Reliability in Large-Scale Machine Learning Research Clusters ↩
-
https://job-boards.greenhouse.io/thinkingmachines/jobs/5013914008 ↩