Nemotron 3 is a family of text-to-text hybrid transformer models developed by NVIDIA Research that comes in three flavors: Nano, Super, and Ultra.
Super
Super has 120.6B parameters with 12B active parameters per token.
Architecture
Super has 88 layers which are predominantly Mamba-2 layers followed by mixture of experts layers. There are also attention layers dispersed throughout, but they are not evenly spaced:
| Segment | Pattern | Mamba | Expert | Attention |
|---|---|---|---|---|
| 1 | MEMEMEM* | 4 | 3 | 1 |
| 2 | EMEMEMEM* | 4 | 4 | 1 |
| 3 | EMEMEMEM* | 4 | 4 | 1 |
| 4 | EMEMEMEMEM* | 5 | 5 | 1 |
| 5 | EMEMEMEMEM* | 5 | 5 | 1 |
| 6 | EMEMEMEMEM* | 5 | 5 | 1 |
| 7 | EMEMEMEMEM* | 5 | 5 | 1 |
| 8 | EMEMEMEM* | 4 | 4 | 1 |
| 9 | EMEMEMEME | 4 | 5 | 0 |
| Total | 40 | 40 | 8 |
The model’s hidden dimension is 4096. In total, there are1
- 40 Mamba-2 layers, each with
- SSM recurrent state:
- head dimension of 64
- 128 Mamba heads
- SSM state size of 128
- 1,048,576 elements at FP322
- 2 MiB of SSM state per layer, independent of input token count, must be cached between decodes
- Convolution state:
- kernel size of 4
- state expansion factor of 2
- SSM recurrent state:
- 8 Attention layers, each with
- 40 Expert layers (actually LatentMoE layers), each with
- 1 shared expert
- intermediate size of 5376
- 512 routed experts (22 active per token)
- latent size of 1024
- intermediate size of 2688
- 1 shared expert
KV cache savings
Because the model replaces full attention with Mamba layers, the model uses significantly less KV cache than a similarly sized transformer that does not use Mamba layers.
Attention cache
The amount of KV cache that must be maintained grows linearly with the sequence length. As more tokens are generated, so too does the KV cache size.
Each token’s state cache for each attention layer is governed by:
- Key matrix:
[num_key_value_heads x head_dim] - Value matrix:
[num_key_value_heads x head_dim]
For Nemotron 3 Super, this comes out to be:
- Key matrix: 2 x 128 = 256 elements, stored in 8-bit precision, for a total of 256 bytes per token
- Value matrix: 2 x 128 = 256 elements, stored in 8-bit precision, for a total of 256 bytes per token
Across all 8 attention layers, the cache size requires 4096 bytes per token in Nemotron 3 Super.
Mamba cache
The Mamba-2 layers have a fixed state cache that does not grow with sequence length. It is governed by
- SSM recurrent state:
[mamba_num_heads x mamba_head_dim x ssm_state_size] - Convolution state:
[(mamba_num_heads x mamba_head_dim + 2 x n_groups x ssm_state_size) x conv_kernel]
For Nemotron 3 Super, this comes out to be
- SSM recurrent state: 128 x 64 x 128 = 1,048,576 elements, stored in 32-bit precision4 for a total of 4 MiB.
- Convolution state: 10,240 x 4 = 40,960 elements, stored in the default model precision (16-bit)4 for a total of 80 KiB.
Across all 40 Mamba-2 layers, the cached size is fixed at around 163 MiB in Nemotron 3 Super.
MTP cache
Nemotron 3 Super also includes optional multi-token prediction (MTP) layers which have a small amount of KV cache. The Huggingface implementation does not include this,1 so I won’t either.
Overall
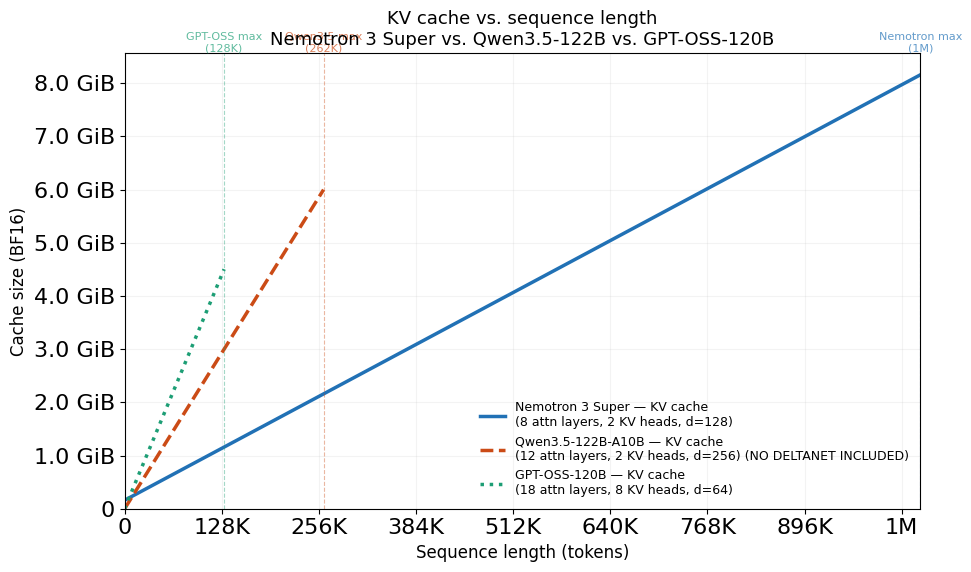
Break-even sequence lengths:
- vs Qwen3.5-122B: 10,440 tokens (this doesn’t include the DeltaNet layers though)
- vs GPT-OSS-120B: 5,801 tokens
Below the break-even, GPT-OSS has a smaller total cache because of Nemotron’s fixed Mamba state. Above it, Nemotron wins as KV savings compound.
Training
It was trained on “approximately 25 trillion tokens,” of which 15,573,172,908,990 (15.6T) tokens were text from across 153 datasets,4 some of which are public. I guess the remaining 9.4T tokens are non-public text tokens?
Footnotes
-
config.json · nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-Base-BF16 at main ↩ ↩2
-
The recurrent state is saved as FP32 because errors compound. See NVIDIA-Nemotron-3-Super-Technical-Report.pdf ↩
-
The model card4 shows a vLLM example with
--kv-cache-dtype fp8. ↩ -
nemotron-3-super-120b-a12b Model by NVIDIA | NVIDIA NIM ↩ ↩2 ↩3 ↩4