LatentMoE is a variant of the mixture of experts architecture that reduces the size of the activation matrix before it gets routed to experts.
Taking Nemotron 3 Super as an example,1
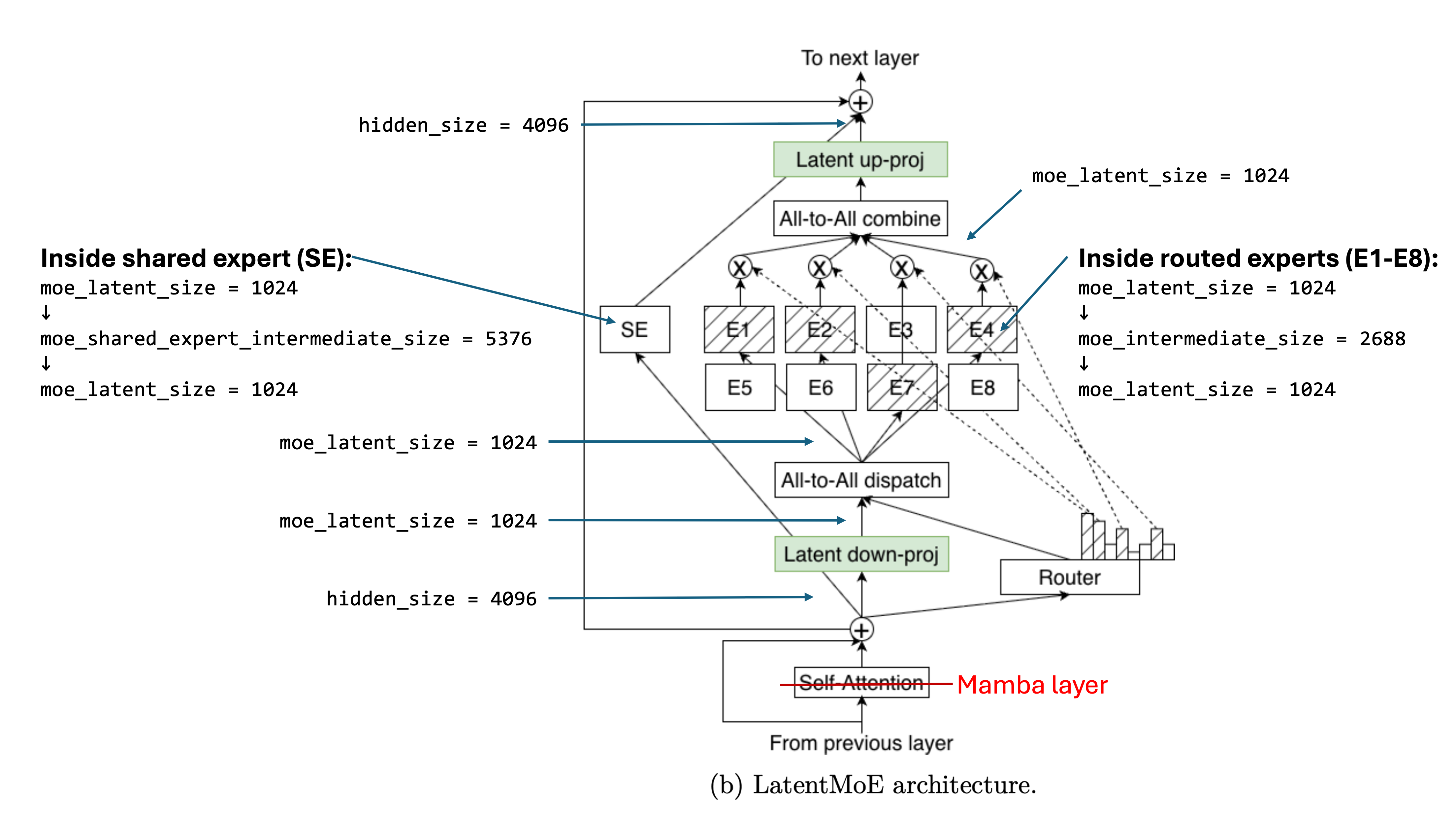
The above nomenclature comes from the Huggingface model configuration.2