Introduction
Note: This page remains under construction, and I will build on it as time permits. It is currently missing (1) diagrams, (2) a complete Implementations section, and (3) a reasonable technical review since I don't really know what I'm talking about.
The term "object storage" has become quite buzzworthy in the enterprise world as a result of Amazon S3's wild successes in being the backing store behind data giants like Instagram and Dropbox. Unfortunately, the amount of marketing nonsense surrounding the term has really diluted what is actually a very promising storage technology that has already begun to make its way into extreme-scale supercomputing.
Object storage offers substantially better scalability, resilience, and durability than today's parallel file systems, and for certain workloads, it can deliver staggering amounts of bandwidth to and from compute nodes as well. It achieves these new heights of overall performance by abandoning the notion of files and directories. Object stores do not support the POSIX IO calls (open, close, read, write, seek) that file systems support. Instead, object stores support only two fundamental operations: PUT and GET.
Key Features of Object Storage
This simplicity gives way to a few extremely important restrictions on what you can do with an object store:
- PUT creates a new object and fills it with data.
- There is no way to modify data within an existing object (or "modify in place") as a result, so all objects within an object store are said to be immutable.
- When a new object is created, the object store returns its unique object id. This is usually a UUID that has no intrinsic meaning like a filename would.
- GET retrieves the contents of an object based on its object ID
To a large degree, that's it. Editing an object means creating a completely new copy of it with the necessary changes, and it is up to the user of the object store to keep track of which object IDs correspond to more meaningful information like a file name.
This gross simplicity has a number of extremely valuable implications in the context of high-performance computing:
- Because data is write-once, there is no need for a node to obtain a lock an object before reading its contents. There is no risk of another node writing to that object while its is being read.
- Because the only reference to an object is its unique object ID, a simple hash of the object ID can be used to determine where an object will physically reside (which disk of which storage node). There is no need for a compute node to contact a metadata server to determine which storage server actually holds an object's contents.
This combination of lock-free data access and deterministic mapping of data to physical locations makes I/O performance extremely scalable, as there are no intrinsic bottleneck when many compute nodes are accessing data across object storage servers.
Note that many object storage implementations treat object immutability with some flexibility; for example, append-only access modes still eliminate many of the locking bottlenecks while improving the utility of the storage.
The Limitations of Object Storage
The simplicity of object storage semantics makes it extremely scalable, but it also extremely limits its utility. Consider:
- Objects' immutability restricts them to write-once, read-many workloads. This means object stores cannot be used for scratch space or hot storage, and their applications are limited to data archival.
- Objects are comprised of data and an object ID and nothing else. Any metadata for an object (such as a logical file name, creation time, owner, access permissions) must be managed outside of the object store. This can be really annoying.
Both of these drawbacks are sufficiently prohibitive that virtually all object stores come with an additional database layer that lives directly on top of the database layer. This database layer (called "gateway" or "proxy" services by different vendors) provides a much nicer front-end interface to users and typically maintains the map of an object ID to user-friendly metadata like an object name, access permissions, and so on.
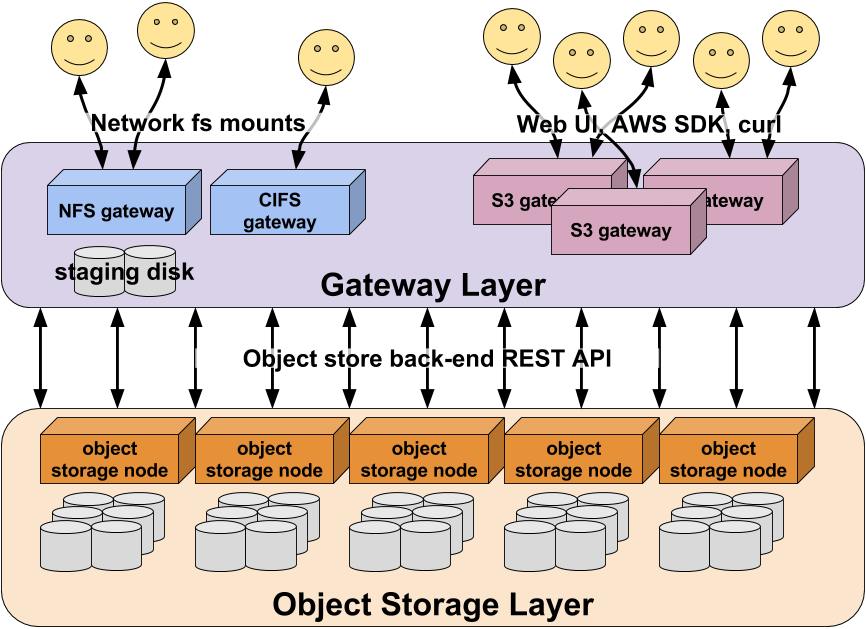
This separation of the object store from the user-facing access interface brings
some powerful features with it. For example, an object store may have a
gateway that provides an S3-compatible interface with user accounting,
fine-grained access controls, and user-defined object tags for applications
that natively speak the S3 REST API. At the same time, a different NFS gateway
can provide an easy way for users to archive their data to the same underlying
object store with a simple cp command.
Because object storage does not attempt to preserve POSIX compatibility, the gateway implementations have become convenient places to store extremely rich object metadata that surpasses what has been traditionally provided by POSIX and NFSv4 ACLs. For example, the S3 API provides a means to associate arbitrary key-value pairs with objects as user-defined metadata, and DDN's WOS takes an even bigger step by allowing users to query the gateway's database of object metadata to select all objects that match the query criteria.
Much more sophisticated interfaces can be build upon object stores as well; in fact, most parallel file systems (including Lustre, Panasas, and BeeGFS) are built on concepts arising from object stores. They make various compromises in the front- and back-end to balance scalability with performance and usability, but this flexibility is afforded by building atop object-based (rather than block-based) data representations.
Although separating user interfaces from the underlying object representation of data affords flexibility, not all such gateways are dual-access gateways. Dual access (or tertiary access, or whatever else) is what allows you to access the same data through multiple interfaces (e.g., writing an object using PUT, but reading it back as if it were a file). At best, dual-access gateways tend to be eventually consistent so that you do not necessarily see data through all gateways as soon as you write it from another.
Object Storage Implementations
This section is very incomplete, but I hope to illustrate some specific engineering components of object storage implementations.
Although the principles of object storage are reasonably simple, there are various ways in which specific object store products differ. In particular, the way data moves when a PUT or GET request is received can vary to provide different resiliency, scalability, and performance.
ShellStore: the simplest example
In this section, I hope to illustrate the simplicity of a basic object store using Ian Kirker's ShellStore, which is a remarkably concise (albeit insane) implementation of an object store.
Its beauty is that it demonstrates the basic ins and outs of how an object store works using simple bash.
DDN WOS
WOS was built to be a high-performance, scalable object store targeted at the high-performance storage market. Because it was built from the ground up, its design is very simple and sensible, and it reflects the benefit of learning from earlier object storage products' design flaws. The simplicity of WOS also makes it a great model for illustrating how object stores in general work. With that being said though, it is used by a number of very large companies (for example, Siri is said to be living on WOS) and has a number of notable features:
- it clearly separates back-end object storage servers and front-end gateways, and the API providing access to the back-end is dead simple and accessible via C++, Python, Java, and raw REST
- objects are stored directly on block devices without a file-based layer like ext3 interposed. DDN markets this as "NoFS"
- erasure coding is supported as a first-class feature, although the code rate is fixed. Tuning durability with erasure coding has to be done with multi-site erasure coding.
- searchable object metadata is built into the backend, so not only can you tag objects, you can retrieve objects based on queries. This is pretty major--most object stores do not provide a way to search for objects based on their metadata
- active data scrubbing occurs on the backend; most other object stores assume that data integrity is verified by something underneath the object storage system
- S3 gateway service is built on top of Apache HBase
- NFS gateways scale out to eight servers, each with local disk-based write cache and global coherency via save-on-close
Until I get a chance to write more about the DDN WOS architecture, there are a few slides that cover the general WOS architecture available.
OpenStack Swift
OpenStack Swift is one of the first major open-source implementations of an enterprise-grade object store. It is what lives behind many private clouds today, but its age has resulted in many sub-optimal design decisions being baked in. Notably,
- it stores objects in block file systems like ext3, and it relies heavily on file system features (specifically, xattrs) to store metadata
- its backend database of object mappings and locations are stored in .gz files which are replicated to all storage and proxy nodes
- container and account servers store a subset of object metadata (their container and account attributes) in replicated sqlite databases
- it is missing important core features such as erasure coding
Until I write up my own interpretation of the Swift architecture, you are welcome to read the official OpenStack Swift architecture documentation.
RedHat/Inktank Ceph
Ceph uses a deterministic hash (called CRUSH) that allows clients to communicate directly with object storage servers without having to look up the location of an object for each read or write. A general schematic of data flow looks like this:

Basic Ceph data path
Objects are mapped to placement groups using a simple hash function. Placement groups (PGs) are logical abstractions that map to object storage daemons (which own collections of physical disk) via the CRUSH hash. CRUSH is unique in that it allows additional OSDs to be added without having to rebuild the entire object-PG-OSD map structure; only a fraction of placement groups need to be remapped to newly added OSDs, enabling very flexible scalability and resilience.
Placement groups own object durability policies, and with the CRUSH algorithm, are what allow objects to be physically replicated and geographically distributed across multiple OSDs.
Ceph implements its durability policies on the server side, so that a client that PUTs or GETs an object only talks to a single OSD. Once an object is PUT on an OSD, that OSD is in charge of replicating it to other OSDs, or performing the sharding, erasure coding, and distribution of coded shards. Intel has posted a good description (with diagrams) on Ceph's replication and erasure coding data paths.
Until I write up a more detailed explanation, here are a few good resources for finding out more about Ceph's architecture:
- The official Ceph architecture documentation
- "Building an organic block storage service at CERN with Ceph," a paper presented at CHEP2013
- "RADOS: a scalable, reliable storage service for petabyte-scale storage clusters," a paper describing the object storage platform that lives underneath Ceph (RADOS) from PDSW'07
Scality RING
I don't actually know much of anything about Scality RING, but it's an object storage platform that is rapidly breaking into the HPC realm and will be a new tier of storage supporting Los Alamos National Labs' Trinity system. A number of people suggested I should include it here as well, so it sounds like I need to learn how Scality does what it does. When I do, I will fill out this section.
Of note, Scality RING is a software-only product (like Swift and Ceph, unlike DDN WOS) that will live on whatever whitebox hardware you want. It has all of the standard gateway interfaces (S3, NFS/CIFS, and REST, called "connectors"), erasure coding, and a scalable design that seems to center on a deterministic hash which maps data to a specific storage node within the cluster. Storage nodes are all peers, and any storage node can answer requests for data living on any other storage node via back-end peer-to-peer transfers.
Until I learn more about the guts of Scality, the best I can provide is this Scality RING slide deck that touches on some architectural detail and refers to specific patents.
Other Products
There are a few more object storage platforms that are worth note, but they are less relevant to the HPC industry because of their target verticals or a few key design points. They reflect some interesting architectural decisions, but I may ultimately drop this section to narrow the focus of this page.
NetApp StorageGRID
NetApp's StorageGRID object storage platform comes from its acquisition of Bycast, and StorageGRID is primarily used in the medical records business. NetApp doesn't talk about StorageGRID much and, from what I can tell, there isn't much to note other than it uses Cassandra as its proxy database for tracking object indices.
I have some notes from a NetApp briefing on StorageGRID, so I will look them over and expand this section if there's anything interesting. If not, this section might disappear in the future.
Cleversafe
Cleversafe is an object storage platform that targets the enterprise market and boasts extreme durability. They sell a software-only product like Scality, but the buy-in is quite peculiar; specifically, Cleversafe clusters cannot be scaled out easily, as you must buy all of your object storage nodes (sliceStors) up front. Instead, you have to buy partially populated storage nodes and add capacity by scaling each one up; when all nodes are scaled, you then have to buy a new cluster.
Of course, this is fine for organizations that scale in units of entire racks, but less practical outside of top-end HPC centers. Indeed, notable customers of Cleversafe include Shutterfly, which spoke about their experiences with 190 PB of Cleversafe object storage at MSST 2016.
Cleversafe is not as feature-complete as other object storage platforms the last time I got a briefing; they provide several REST interfaces ("accessers") including S3, Swift, and HDFS, but NFS/CIFS-based access must come from a third party on top of S3/Swift. Again, large enterprises often write their own software to speak S3, so this is less of an impediment at scale.
Peripheral Technologies
The following technologies, while not strictly object storage platforms, are complementary to or representative of the spirit of object stores.
iRODS - object storage without the objects or storage
iRODS which provides the gateway layer of an object store without the object store underneath. It is worth mentioning here because it can turn a collection of file systems into something that looks more like an object store by stripping away the POSIX compliance in favor of a more flexible and metadata-oriented interface. However, iRODS is designed for data management, not high-performance.
I will include more information about iRODS as time permits. Until then, TACC's user guide for its iRODS system will give you a very concise idea of what iRODS allows you to do.
MarFS - a POSIX-ish interface to object storage
MarFS is a framework, developed at Los Alamos National Laboratory, that provides
an interface to object storage that includes many familiar POSIX operations.
Unlike a gateway that sits in front of an object store, MarFS provides this
interface directly on client nodes and transparently translates POSIX
operations into the API calls understood by the underlying object store. It is
designed to be lightweight, modular, and scalable, and in many ways, it
accomplishes what, for example, the llite client does in terms of mapping
POSIX calls issued on a storage client to calls understood by the underlying
object-based Lustre data representation.
The current implementation in use at LANL uses a GPFS file system to store the metadata that a regular POSIX file system would present to its users. Instead of storing the data on GPFS as well, all of the files on this index system are stubs--they contain no data, but they have the ownership, permissions, and other POSIX attributes of the objects they represent. The data itself lives in an object store (provided by Scality, in the LANL implementation), and the MarFS FUSE daemon on each storage client uses the GPFS index file system to connect POSIX I/O calls with the data living in object storage.
Because it connects storage clients directly to the object store rather than acting as a gateway, MarFS only provides a subset of POSIX I/O operations. Notably, because the underlying data are stored as immutable objects, MarFS does not allow users to overwrite data that already exists.
I gleaned most of the above description of MarFS from public presentations and follow-up discussion with the creators of MarFS. I recommend looking at a MarFS presentation given at MSST 2016 for more details.